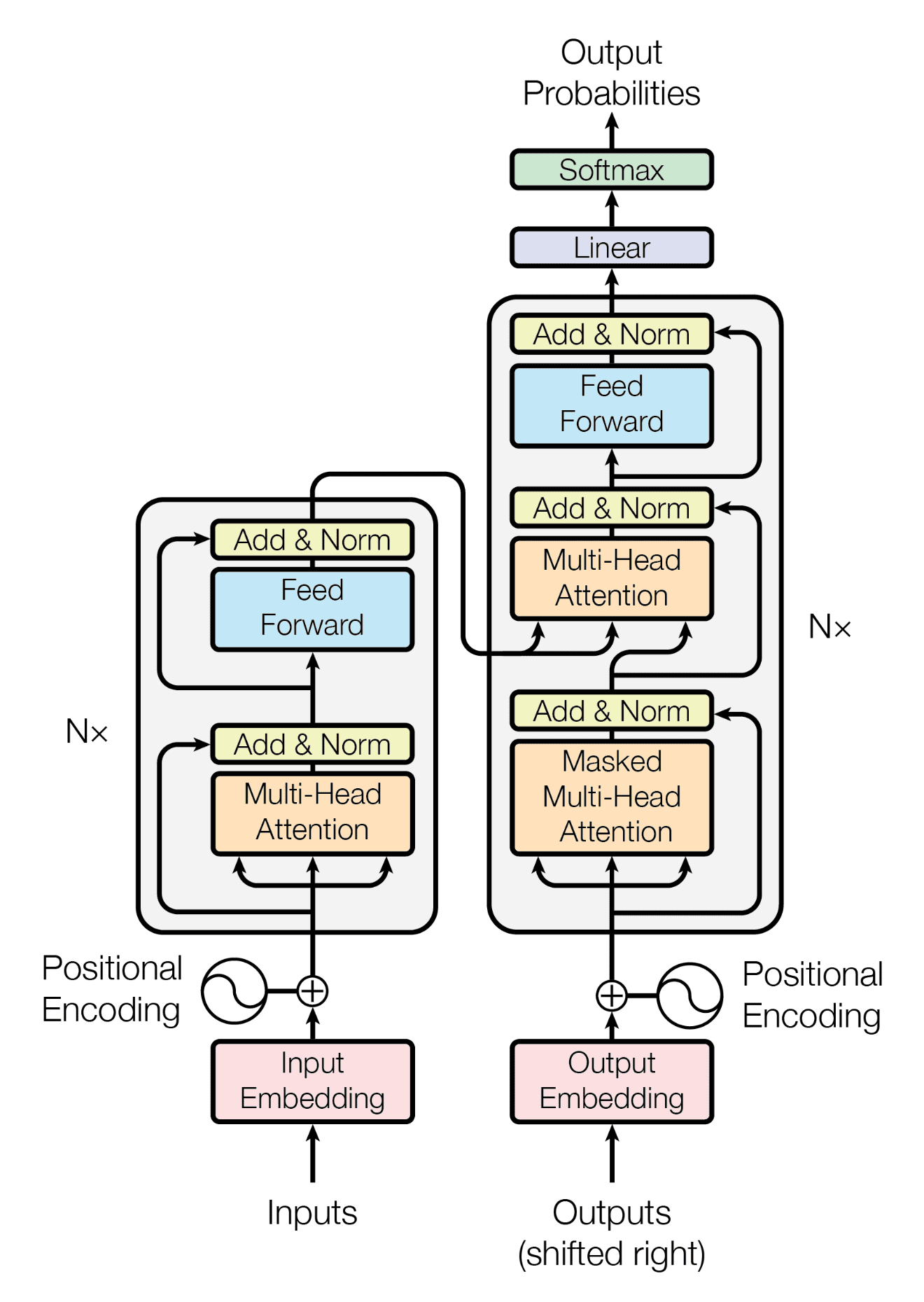
In recent years, the field of Natural Language Processing (NLP) has witnessed a revolutionary change with the introduction of large language models based on the transformer architecture. This transformation has significantly improved the performance of natural language tasks over the earlier generation of Recurrent Neural Networks (RNNs). The power of the transformer architecture lies in its ability to learn the relevance and context of all words in a sentence, not just in relation to their neighboring words but to every other word in the sentence.
If you wanna learn how to fine tune these models check the post: click here
Table of Contents
- Introduction to LLMs
- The Encoder: Breaking Down Its Components
- The Decoder: Breaking Down Its Components
- Pre-training and Fine-tuning
- The Role of Pre-training and Fine-tuning
- Applications of LLMs
- Future Prospects of LLMs
- Conclusion
- FAQs
Large Language Models (LLMs) are intricate structures that have revolutionized natural language processing. They consist of two distinct parts: the encoder and the decoder, which work in conjunction with each other. These components share several similarities and play crucial roles in the model’s operation. Let’s delve deeper into the workings of LLMs, focusing on the encoder and decoder in this section:
The Encoder: Breaking Down Its Components
Tokenization and Embedding Layer
Before processing texts in the model, words must be tokenized, converting them into numerical representations. Each token corresponds to a unique position in the model’s dictionary of words. Tokenization methods can vary, and the choice of tokenizer used during training should be maintained during text generation. The embedding layer then maps each token ID to a multi-dimensional vector in an embedding space. These vectors encode the meaning and context of individual tokens in the input sequence.
Positional Encoding
As the model processes input tokens concurrently, preserving information about word order becomes crucial. This is where positional encoding comes in. It is added to the input data to ensure that the model retains the relevance of each word’s position in the sentence.
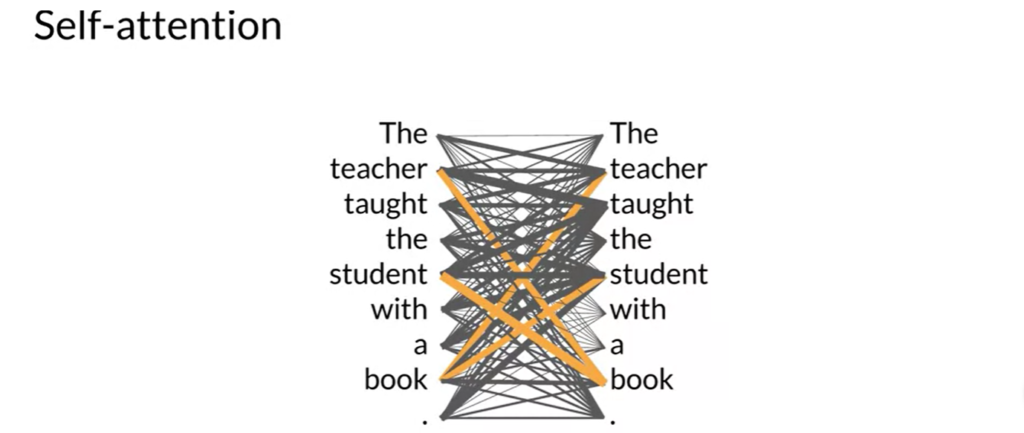
Self-Attention Layer
The input tokens, along with positional encodings, are passed through the self-attention layer, which computes attention weights for each word in relation to all other words in the sequence. This multi-headed self-attention mechanism allows the model to learn different aspects of language, enhancing its understanding.
For example in the sentence “The teacher taught the student with a book”. Self attention layer will check every word relation with other as shown below:
Feed-Forward Network
After self-attention, the output is processed through a fully-connected feed-forward network. The resulting vectors contain logits, representing the probability scores for each token in the tokenizer dictionary. Following self-attention, the output passes through a fully-connected feed-forward network. This network generates vectors containing logits, which represent the probability scores for each token in the tokenizer dictionary.
SoftMax Layer
The logits are normalized into probability scores for each word using the softmax layer. This process results in the selection of the most likely predicted token, while still allowing for various methods to vary the final selection from the probability vector. To make sense of the logits and select the most likely predicted token, the softmax layer comes into play. This layer normalizes the logits into probability scores for each word. This normalization process enables the model to choose the most probable token while still allowing for flexibility in the final selection from the probability vector.
The Decoder: The Components
Self-Attention Mechanism
Much like the encoder, the decoder relies on a self-attention mechanism. However, in the decoder’s case, it doesn’t consider the entire input sequence at once. Instead, it focuses on the previously generated words in the output sequence. This self-attention helps the decoder maintain coherence and relevance in the text it generates.
Masked Self-Attention
To prevent the decoder from cheating by looking ahead in the output sequence, a masking mechanism is applied during self-attention. This means the decoder only considers words generated before the current word, ensuring that it follows a sequential and logical flow.
Context from the Encoder
The decoder receives information from the encoder, which includes the final hidden states and the output of the encoder’s self-attention mechanism. This information acts as a guide, helping the decoder understand the context of the input and produce contextually relevant output.
Language Generation
The main role of the decoder is language generation. It takes the context and previously generated words into account to predict the next word in the sequence. This process is repeated iteratively to produce coherent and contextually appropriate text.
Beam Search and Sampling
To enhance the quality of generated text, decoders often use strategies like beam search or random sampling. Beam search explores multiple potential word sequences, while sampling introduces an element of randomness. These strategies contribute to the richness and diversity of the generated text.
Pre-training and Fine-tuning
LLMs undergo two essential phases: pre-training and fine-tuning. During pre-training, models learn from vast amounts of text data to acquire general language understanding. Fine-tuning tailors the model for specific tasks, making it more accurate and context-aware.
The Role of Pre-training and Fine-tuning
The process of pre-training and fine-tuning is crucial in shaping an LLM’s capabilities. Pre-training exposes the model to a massive corpus of text, helping it grasp grammar, context, and semantics. Fine-tuning narrows the focus, allowing the model to specialize in tasks like language translation, sentiment analysis, or chatbot responses.
Applications of LLMs:
LLMs have found applications in numerous domains. They power chatbots, assist with content generation, facilitate language translation, and aid in sentiment analysis. Their versatility makes them invaluable in natural language processing tasks.
Future Prospects of LLMs
The future of LLMs is promising. Continued research and development will likely lead to even more powerful models with enhanced language capabilities. These models will play a vital role in shaping the future of AI-powered applications.
Conclusion
The transformer architecture has revolutionized NLP by enabling large language models to learn the relevance and context of words efficiently. The self-attention mechanism and the ability to process tokens in parallel contribute to the model’s remarkable performance on language-related tasks. This technology has paved the way for significant advancements in various NLP applications, from machine translation to sentiment analysis, making language models more powerful and versatile than ever before.
FAQ’s:
What is self-attention in the transformer architecture?
Self-attention is a mechanism that allows the model to weigh the relevance of each word concerning every other word in the input sequence, enabling better contextual understanding.
How does the transformer architecture handle tokenization?
Tokenization converts words into numerical representations (token IDs), and each token is mapped into a vector in an embedding space, encoding its meaning and context.
What is the purpose of positional encoding in the transformer architecture?
Positional encoding preserves information about the word order and ensures that the model retains the significance of each word’s position in the sentence.
How does the transformer architecture learn different aspects of language?
The transformer’s multi-headed self-attention mechanism allows each attention head to learn different aspects of language independently during training.
What makes the transformer architecture superior to earlier RNN-based models?
The transformer’s ability to attend to all words in a sentence simultaneously, along with self-attention, significantly improves its language understanding, surpassing the limitations of earlier RNNs.
What is the Importance of Self-Attention ?
The key attribute that sets the transformer architecture apart is self-attention. This mechanism enables the model to attend to different parts of the input sequence, capturing contextual dependencies between the words. It analyzes the relationships between tokens, assigning attention weights to each word in the input sequence concerning every other word. This self-attention is pivotal in enhancing the model’s ability to understand language effectively.
The Work